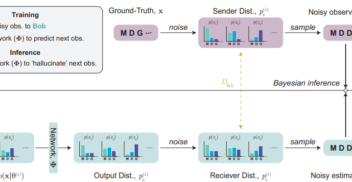
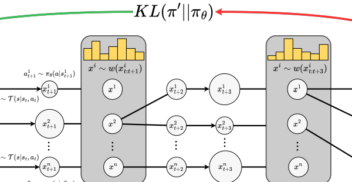
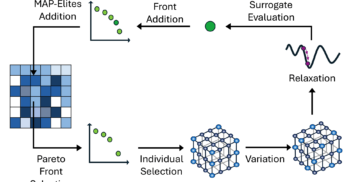
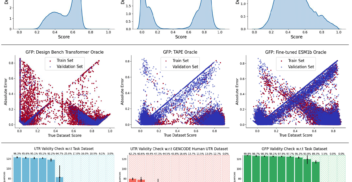
InstaDeep’s in-house research team contributes to the latest advancements in AI - from the fundamentals of machine learning to robotics and deep reinforcement learning. Our published research has been presented at world-leading conferences such as NeurIPS, ICLR and ICML.
Timothy Atkinson | Thomas D. Barrett | Scott Cameron | Bora Guloglu | Matthew Greenig | Louis Robinson | Alex Graves | Liviu Copoiu | Alexandre Laterre
A blog post covering our recent publication: Christopher W. F. Parsonson, Alexandre Laterre, and Thomas D. Barrett, ‘Reinforcement Learning for Branch-and-Bound Optimisation using Retrospective Trajectories’, AAAI’23: Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence, 2023 Branch-and-bound solvers for combinatorial optimisation Formally, ‘combinatorial optimisation’ (CO) problems consider the task of assigning integer values to a… Read more »
Continuing the innovation and application of machine learning to the hardest and most impactful challenges, InstaDeep is pleased to share its new breakthrough on applying reinforcement learning to complex combinatorial problems. Our new work, “Population-Based Reinforcement Learning for Combinatorial Optimization” introduces a new framework for learning a diverse set of complementary agents, and obtains state-of-the-art… Read more »
InstaDeep is delighted to announce that a collaborative research project with a team from the University of Oxford on “Autoregressive neural-network wavefunctions for ab initio quantum chemistry” has been published in Nature Machine Intelligence magazine. The paper was authored by Dr Thomas Barrett of InstaDeep as well as Prof A. I. Lvovsky and Aleksei Malyshev… Read more »
With the continuous growth of the global economy and markets, resource imbalance has risen to be one of the central issues in real logistic scenarios. In particular, we focus our study on the marine transportation domain and show how Multi-Agent Reinforcement Learning can be used to learn cooperative policies that limit the severe disparity in… Read more »
(Part 2/4) In our introduction to meta-reinforcement learning, we presented the main concepts of meta-RL: Meta-Environments are associated with a distribution of distinct MDPs called tasks. The goal of Meta-RL is to learn to leverage prior experience to adapt quickly to new tasks. In Meta-RL, we learn an algorithm during a step called meta-training. At meta-testing, we apply this… Read more »
(Part 1/4) The recent developments in Reinforcement Learning (RL) have shown the incredible capacity of computers to outperform human performance in many environments such as Atari Games [1], Go, chess, shogi [2], Starcraft II [3]. This performance results from the development of Deep Learning and Reinforcement Learning methods like Deep Q-Networks (DQN) [4] and actor-critic methods [5, 6, 7, 8]. However, one essential advantage of… Read more »
Strictly Necessary Cookie should be enabled at all times so that we can save your preferences for cookie settings.
If you disable this cookie, we will not be able to save your preferences. This means that every time you visit this website you will need to enable or disable cookies again.