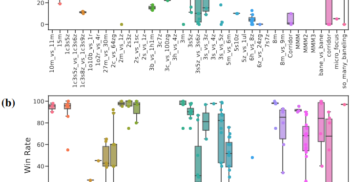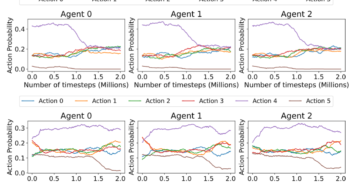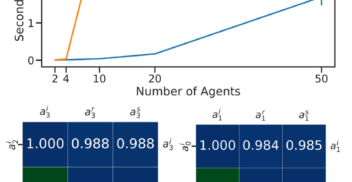


Divanisha Patel was working for a bank when the possibilities AI holds for positive change caught her imagination. Divanisha decided to make the jump from finance to AI. Now a...

From Finance to AI: Meet Divanisha Patel...
on Apr 04, 2024 | 01:16pm
InstaDeep delivers AI-powered decision-making systems for the Enterprise. With expertise in both machine intelligence research and concrete business deployments, we provide a competitive advantage to our customers in an AI-first world.
Learn MoreOur latest updates from across our channels
on Apr 04, 2024 | 01:16pm
Divanisha Patel was working for a bank when the possibilities AI holds for positive change caught her imagination. Divanisha decided to make the jump from finance to AI. Now a...

on Mar 26, 2024 | 05:22pm
Can competitive swimming prepare you for the dive into AI? Once a competitive swimmer in national and international competitions for 18 years, Narimane Hennouni brings a c...

on Mar 22, 2024 | 05:25pm
Imagine waking to a world where every genetic sequence is a code waiting to be deciphered, pieces in a giant puzzle. That’s everyday life for Maša Roller, a senior computati...

on Feb 13, 2024 | 04:04pm
TIME Magazine awarded CEO and Co-Founder Karim Beguir a TIME100 Impact Award for leading InstaDeep's work to help communities and business tackle tough problems with AI. Ka...

on Jan 15, 2024 | 02:53pm
InstaDeep CEO Karim Beguir has been named one of the 100 Most Influential Africans by a leading pan-African news magazine. The New African cited his leadership and innovation in A...

on Dec 11, 2023 | 01:00pm
Two InstaDeep Tunis-based AI researchers will present at NeurIPS 2023 NAML: North African Machine Learning workshop on multi-script handwriting recognition and what happens Multi...

on Dec 10, 2023 | 09:00pm
InstaDeep Research Engineer Shikha Surana presents her work on COMPASS (Combinatorial Optimization with Policy Adaptation using Latent Space Search) at the NeurIPS 2023 Women in M...

on Dec 08, 2023 | 01:21pm
• An InstaDeep record of 13 papers are being presented at world's top AI and machine learning conference • Breadth of research ranges from Decision-Making AI to breakthroug...

on Nov 02, 2023 | 09:36am
InstaDeep joined leading AI nations, companies and civil society organisations at the table for the first-ever AI Safety Summit – looking at the future of AI and how it can be d...

on Oct 23, 2023 | 06:06pm
Instadeep used reinforcement learning on Cloud TPUs to improve DeepPCB, its AI-driven Printed Circuit Board (PCB) design product. Authors: Armand Picard, Software Engine...