Today, InstaDeep introduces Mava: a research framework specifically designed for building scalable, high-quality Multi-Agent Reinforcement Learning (MARL) systems. Mava provides useful components, abstractions, utilities, and tools for MARL and allows for easy scaling with multi-process system training and execution while providing a high level of flexibility and composability.
To support the field of single-agent reinforcement learning (RL), several frameworks have emerged such as Dopamine, RLlib, and Acme (to name just a few), that aim to help the community build effective and scalable agents. However, a limitation to the existing frameworks is that very few focus exclusively on MARL, an increasingly active research field with its own set of challenges and opportunities. We aim to fill this gap with Mava. By focusing on MARL, Mava is designed to leverage the natural structure of Multi-Agent problems. This ensures Mava remains lightweight and flexible while at the same time providing tailored support for MARL.
Our efforts to open-source Mava stem from a passion for contributing to the development of MARL, supporting open collaboration, and our commitment to being of service to the wider community. We have benefited greatly from open-source software, and therefore, in a similar way, want to give back and be of benefit to others.
Why MARL?
In Xhosa, one of South Africa’s eleven official languages, “MAVA” means experience or wisdom. A famous African proverb says, “If you want to go quickly, go alone. If you want to go far, go together.” This ancient proverb resonates with the wisdom of generations on the value of teamwork. Only by working together, has humanity been able to accomplish some of its greatest achievements. In the modern world of today, this has never been more true. The problems we face are distributed, complex and difficult to solve and often require sophisticated strategies of cooperation for us to make any progress. From the standpoint of using AI for problem-solving, this drives us to harness and develop useful computational frameworks for decision-making and cooperation. One such framework is multi-agent reinforcement learning (MARL).
MARL extends the decision-making capabilities of single-agent RL to the setting of distributed decision-making problems. In MARL, multiple agents are trained to act as individual decision-makers of some larger system, while learning to work as a team. The key difference between MARL and single-agent RL is that MARL can be applied in situations where the problem becomes exponentially more difficult to solve as it scales. For example, in managing a fleet of autonomous vehicles for a growing population, the number of navigation decisions that must be made at any given time scales exponentially with the size of the fleet. This quickly becomes intractable for single-agent approaches whereas for MARL, is an opportunity to shine.
Many of humanity’s most important practical problems are reminiscent of the one just described, for instance, the need for sustainable management of distributed resources under the pressures of climate change, or efficient inventory control and supply routing in critical distribution networks, or robotic teams for rescue missions and exploration. We believe MARL has enormous potential to be applied in these areas. However, although MARL can make problems of this kind tractable, MARL introduces other difficulties such as the need for decentralized coordination. To be fully effective at scale in novel situations, it is often required that new strategies and techniques be developed through further research.
A research framework for MARL
Mava aims to provide several useful and extendable components for making it easier and faster to build Multi-Agent systems. These include custom MARL-specific networks, loss functions, communication, and mixing modules. Perhaps the most fundamental component is the system architecture. The architecture of a system defines the information flow between agents in the system. In MAVA, several architectural options are available for system design, from independent agents to centralized training schemes and networked systems.
Furthermore, several MARL baseline systems have already been implemented in Mava. These implementations serve as examples showcasing Mava’s reusable features and allow existing MARL algorithms to be more easily reproduced and extended.
MARL at scale
So how does it all work? At the core of Mava is the concept of a system. A system refers to a full MARL algorithm specification consisting of the following components: an executor, a trainer, and a dataset. The executor is a collection of single-agent actors and is the part of the system that interacts with the environment, i.e. performs an action for each agent and observes each agent’s reward and next observation. The dataset stores all of the information generated by the executor. All data transfer and storage is handled by Reverb. The trainer is a collection of single-agent learners, responsible for sampling data from the dataset and updating the parameters for every agent in the system.
The system executor may be distributed across multiple processes, each with a copy of the environment. Each process collects and stores data that the trainer uses to update the parameters of the actor-networks used within each executor. The distribution of processes is defined through constructing a multi-node graph program using Launchpad. Consequently, Mava can run systems at various levels of scale without changing the underlying system code.
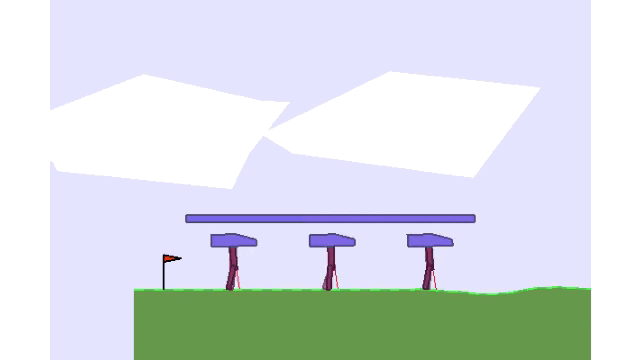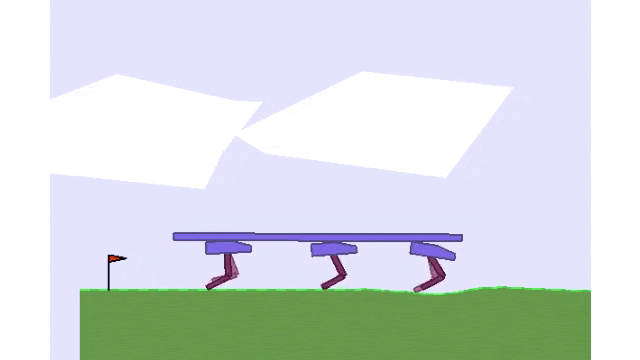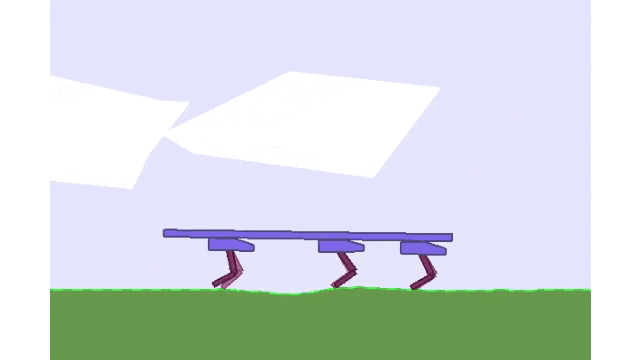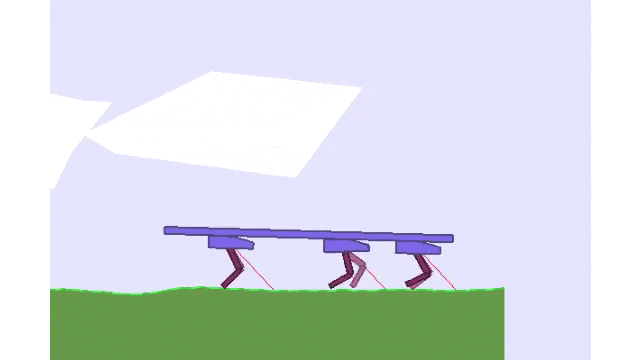
Using Mava to train three agents to walk while balancing a beam in the Multi-Walker environment.
On the shoulders of giants
Mava is indebted to several open-source libraries and would not have existed without them. In particular, Mava is built on top of DeepMind’s Acme framework and was heavily inspired by its design. It integrates with, and greatly benefits from, a wide range of already existing single-agent RL components made available in Acme. Furthermore, we inherit the same RL ecosystem built around Acme. Most notably, we use Reverb for data flow management and support simple scaling using Launchpad. We have also been influenced and made use of many other libraries including PyMARL and OpenSpiel as well as environment-specific libraries such as PettingZoo, Flatland, RoboCup, and the Starcraft Multi-Agent Challenge (SMAC).
We greatly appreciate the huge effort the various teams have put into these libraries and thank them for their contribution to the community and for enabling us to build on their work.
From research to development
InstaDeep’s engineers tackle some of the toughest real-world problems, not only at a macro level, such as scheduling thousands of trains across a vast network but also at a micro level, such as routing electronic circuit boards in hours, instead of days or months. The collaboration between our research teams and engineers is a key ingredient to these successes. The Mava framework goes one step further by offering a frictionless transition from our in-house research to product development, creating synergies between our teams. The flexibility of the framework and its capacity to seamlessly scale is a critical ingredient for our research and engineering teams to deliver new products, services, and research breakthroughs that were previously out of reach.
Conclusion
In this post, we presented Mava, our open-source framework for distributed MARL. We are excited about the future of Mava, its growth, and its ongoing development. We have big plans in store! And see this release as only the beginning. Not only for making our research in MARL more efficient and scalable and sharing our efforts with the community but also for using Mava directly in our applied projects at InstaDeep.
You can find more information, source code, and examples in Mava’s Github repository. For a more detailed description of Mava’s design, along with further results for our current baseline implementations, please see our research paper.
Acknowledgements
The core development team for Mava includes Arnu Pretorius, Kale-ab Tessera, and Andries P. Smit. We greatly acknowledge the contributions of several research interns namely, Claude Formanek, Kevin Eloff, St John Grimbly, and Siphelele Danisa. We also want to thank Lawrence Francis and Femi Azeez for additional contributions to the code base and Bader Klidi, Nidhal Liouane, Aliou Kayantao, and Zohra Slim for the animations and design work. We thank the following people for their external supervision and input: Jonathan Shock, Herman Kamper, Willie Brink, Herman Engelbrecht, Alexandre Laterre, and Karim Beguir. Finally, we thank Matt Hoffman, Gabriel Barth-Maron, and Bobak Shahriari from the Acme team for a helpful discussion. The project was led by Arnu Pretorius.