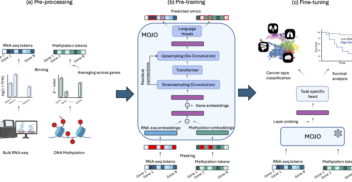
TL;DR: Integrating multiple biological data types gives oncologists a much richer picture of a patient's cancer. However, effectively training AI on massive amounts of highly comp...

MOJO: Decoding the Tumor with Multimodal AI...
on Jul 08, 2026 | 11:03am