
Disclaimer: All claims made are supported by our research paper: A Flexible Antibody Foundation Model Based on Bayesian Flow Networks unless explicitly cited otherwise.
Antibodies play an important role in the adaptive immune response. By selectively recognising and binding to specific antigens—such as viruses or bacteria—they neutralise threats and are essential to both acute and long-term immunity.
This ability to target a wide range of molecules has made antibodies indispensable to therapeutic development, fueling a market valued at $252.6 billion in 2024, with projections reaching $0.5 trillion by 2029.
Therapeutic antibodies consistently make up a major share of new clinical trials. Since 2020, at least 12 antibody therapies have entered the US or EU market every year. Yet, despite their success, antibody development remains an intricate and resource-intensive process—one that AI-driven approaches aim to transform.
Why is antibody development so challenging?
Even when considering only germline antibodies, the estimated number of possible sequences is enormous, ranging between 10 billion and 100 billion—a formidable landscape to navigate.
Adding to this complexity is the fact that not all antibodies are created equal. To be effective for therapeutic use, an antibody must bind precisely to its target while avoiding unintended interactions, and be free of liabilities that could hinder its clinical viability, such as aggregation propensity, poor stability, or low expression levels.
Engineering a therapeutic antibody is therefore a multi-objective optimisation process, typically beginning with the identification of an initial binder—a sequence that shows potential in attaching to a specific target.
However, this sequence is rarely perfect from the start and traditionally undergoes refinement through a case-specific, iterative pipeline 1 of computational and laboratory-based approaches, aiming to improve it through a series of independent steps. For example, in early candidate development a scientist may have an antibody that looks promising for therapeutics, but does not appear to be compatible in the human body. The antibody is improved through a process called humanisation to minimise the risk of an unwanted immune response, while ensuring its desirable properties remain intact.
Advancements in AI are playing an increasingly significant role in therapeutic antibody optimisation, however typical models focus on either sequence generation or property prediction—rarely both. Since these methods traditionally operate in isolation and rely on different tools for each step, optimising one property (such as humanisation) often comes at the expense of another (such as stability), resulting in inefficiencies and trade-offs.
We believe that by unifying these tasks into a single generative framework, AbBFN2 has the potential to enhance efficiency for scientists who want to optimise multiple antibody properties simultaneously.
What is AbBFN2?
Built on the Bayesian Flow Network (BFN) paradigm, AbBFN2 extends our ProtBFN model into a multimodal framework, delivering a flexible tool for antibody design and optimisation.
Through extensive training on diverse antibody sequences, AbBFN2 models 45 different modalities, enabling it to streamline multiple tasks simultaneously while maintaining high accuracy. Unlike conventional approaches that require retraining to accommodate new tasks, AbBFN2 jointly models sequence, genetic, and biophysical attributes within a unified generative framework.
The model can adapt to user-defined tasks by conditionally generating any subset of attributes when given values for the others—enabling a steerable and flexible approach to antibody design. This provides users with a framework for defining and achieving a wide range of optimisation goals. When combined with domain expertise, AbBFN2’s interactive capabilities have the potential to enhance development campaigns and accelerate antibody discovery.
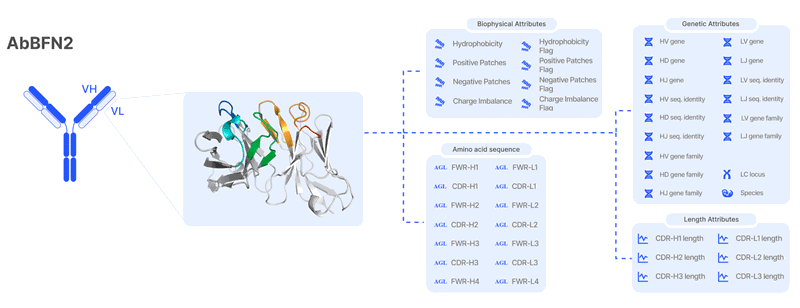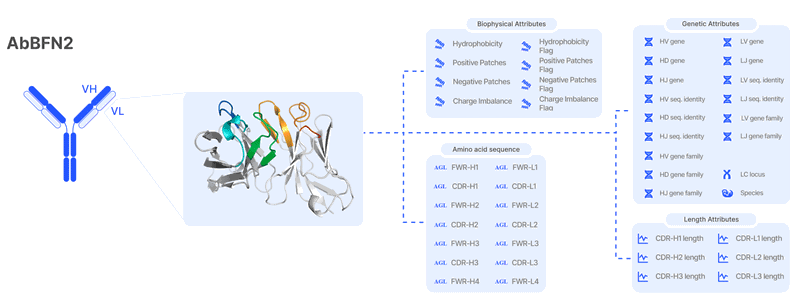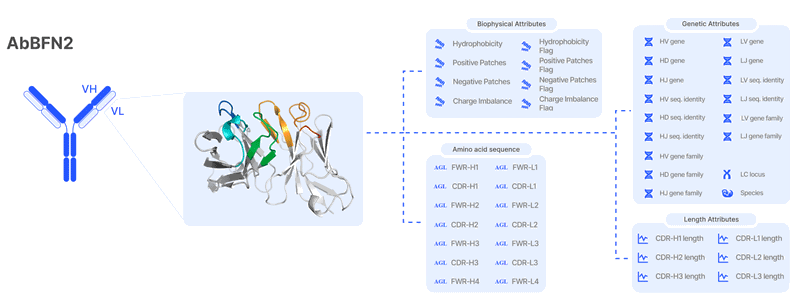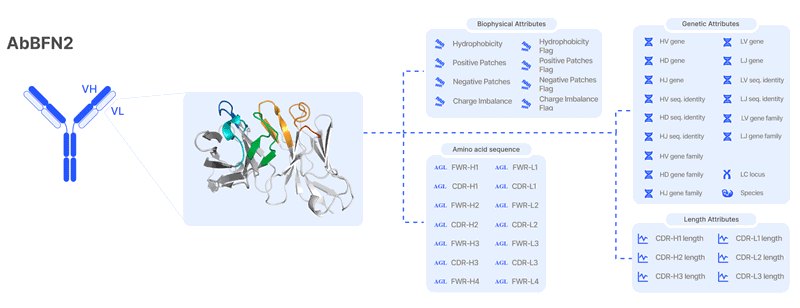
What can it do?
To evaluate AbBFN2’s real-world performance, we tested the model across four key use-cases in therapeutic antibody development—demonstrating its accuracy, and accessibility across critical design tasks.
Unconditional generation
To determine whether AbBFN2 has internalised the fundamental rules governing antibody sequence space, we assessed its ability to generate antibodies unconditionally—without task-specific prompting or conditioning.
We sampled sequences from the model, alongside their associated metadata, and compared them to natural antibodies across a range of biologically meaningful metrics. These included properties of the complementarity-determining regions (CDRs)—the key segments of an antibody responsible for antigen binding.
AbBFN2-generated sequences closely matched the natural distribution of CDR loop lengths (Figure 2a), amino acid propensities, and sequence diversity. Notably, when these sequences were folded using ImmuneBuilder, they aligned with structural motifs observed in natural antibodies—despite not being explicitly trained on structural information, and evaluated only on held-out antibody sequences (Figure 2b, Figure 2c).
Beyond the CDRs, AbBFN2 also recapitulated the genetic landscape of real antibodies. It faithfully captured conditional distributions, involving gene pairing propensities within and between the variable heavy (VH) and variable light (VL) chain domains, implying a nuanced understanding of antibody generation. To validate this further, we tested for training data memorisation and confirmed that the model generates sequences distinct from those seen during training—affirming its ability to reflect the real-world statistical makeup of antibody sequences.

Sequence annotation
Next, we considered AbBFN2’s ability to infer key attributes from sequence alone—sequence annotation. In this setting, the model receives an antibody sequence and is asked to predict all associated metadata, including species, gene usage, and developability metrics.
AbBFN2 performs well across all evaluated tasks, consistently matching existing tools. Notably, the model accurately predicted Therapeutic Antibody Profiler (TAP) flags—development liabilities—directly from sequence, a task that is particularly challenging when only sequence information is available. This ability suggests that AbBFN2 has implicitly learned to reason about structural effects, despite not being explicitly trained on structural data.
The model has proven to be successful in predicting genetic attributes that are typically difficult to infer from amino acid sequences alone. This includes accurate identification of heavy and light chain V, (D), and J genes, highlighting a strong understanding of antibody recombination patterns and lineage information.
Sequence inpainting
Sequence inpainting involves completing an antibody sequence when only partial sequence information is available. This is particularly useful when redesigning specific regions—such as CDR loops, the VH–VL interface, or a targeted set of residues—while maintaining overall structural and functional integrity.
We evaluated AbBFN2’s ability to recover the missing regions of an antibody, particularly at the interface between the VH and the VL chains. The model successfully reconstructed natural VH–VL pairings, demonstrating its ability to understand the intricate dependencies between chains and generate sequences that maintain structural compatibility (Figure 3).
Additionally, conditioning the model on metadata, such as framework sequence and gene segments, significantly improved CDR prediction accuracy, underscoring the value of conditioning on informative attributes. These results reinforce AbBFN2’s ability to reason contextually across antibody regions, enabling intelligent completion and editing of real-world antibody sequences.

Figure 4 (right) Shows AbBFN2’s ability to predict immunogenicity. The confidence that the model has in a sequence being of human origin is correlated with the immunogenicity risk of known clinical-stage therapeutics. >99% of antibodies that AbBFN2 confidently classifies as human present low to medium immunogenicity risks. Source: Internal
Sequence humanisation
AbBFN2 performs sequence humanisation by learning the likelihood that a given antibody will elicit an adverse immune reaction upon administration.
To test this, we first assessed AbBFN2’s ability to estimate the humanness of 211 clinical-stage antibodies and found that sequences the model evaluated as more human were associated with fewer observed immunogenic responses. This validates how AbBFN2’s humanness score correlates with real-world immune outcomes, establishing it as a reliable signal for subsequent optimisation.
Given these results, we used the humanness score as a guiding metric to reduce immunogenicity risks in 25 therapeutic antibodies—distinct from the 211 used in the previous example—for which experimentally humanised variants exist. In this setting, the model accurately selected human-compatible variants, closely mirroring the experimentally derived sequences in both the number of mutations introduced and their locations within the antibody structure. This suggests that AbBFN2 is not only learning how to reduce immunogenicity, but doing so in a biologically plausible and efficient manner.
Multi-objective optimisation
We evaluated AbBFN2’s capabilities for multi-round, multi-objective optimisation, focusing on sequence humanisation and developability. The model efficiently reduces immunogenicity—often reaching a high probability of being human within a single recycling iteration.
To extend this analysis, we applied AbBFN2 to 91 non-human sequences, optimising each for both human-likeness and developability. For 63 of these sequences, the model achieved both objectives within just 2.5 hours—a task that would traditionally take weeks to months per sequence in an experimental setting.
Conditional library generation
We tested AbBFN2’s ability to generate antibody libraries enriched for rare and highly specific characteristics—a critical capability for accelerating discovery. To do this, we conditioned generation on: partial sequence context, a target HV gene, a defined CDR-L3 loop length, a specific light chain locus, and favourable developability attributes.
AbBFN2 successfully produced 1,715 out of 2,500 sequences that met all requirements simultaneously. These sequences were not only valid and unique, but also exhibited natural-like behaviour across additional properties, demonstrating that the model internalises the broader antibody space beyond the explicitly conditioned features (Figure 5).
As a case study, we applied this task to antibodies comprising rare attributes that are rarely found together in natural repertoires. AbBFN2 generated sequences with similar properties—distinct from those in training—and achieved a more than 56,000-fold higher likelihood of satisfying all requested attributes compared to unconditional sampling by either a standard protein language model or AbBFN2 itself.
This level of conditional control is particularly significant—unlike traditional models that require retraining or fine-tuning for specific design goals, AbBFN2 performs these tasks without additional training—greatly lowering the barrier to targeted antibody library generation.

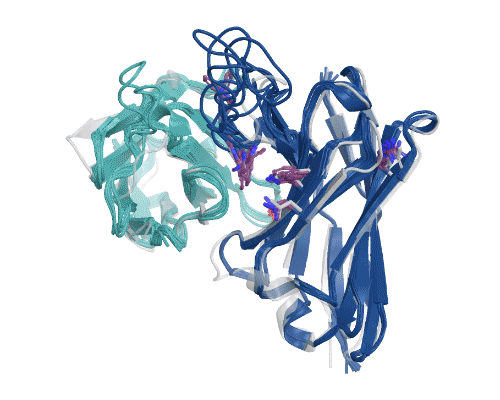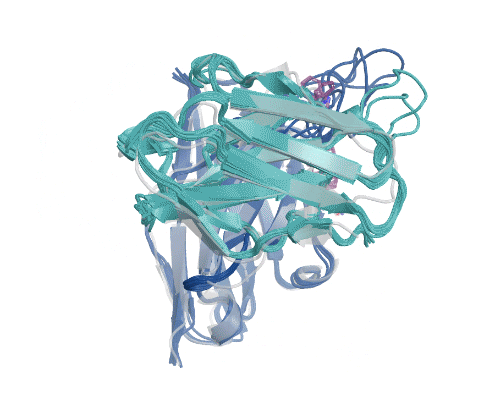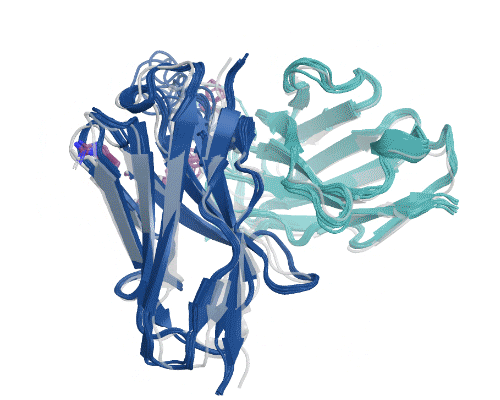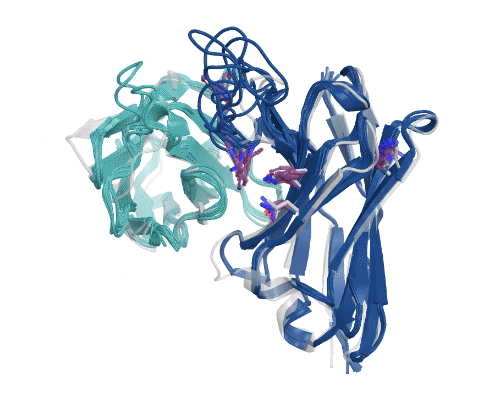
Figure 5: Illustration of AbBFN2’s multi-objective design capabilities. Comparison demonstrates how frequently requested features are in the held-out OAS data and the conditionally generated AbBFN2 samples. (Right) a set of conditionally generated samples (navy and cyan) folded and superimposed on a known antibody with the requested attributes. The VH is shown in navy and the VL in cyan, with specific residues of interest shown in purple. Source: Internal.
What does this mean?
AbBFN2 is more than just another antibody design model—it offers a distinct approach. By leveraging this technology, pharmaceutical companies gain access to a unified and flexible framework for interacting with antibody sequence data. With its ability to optimise multiple properties simultaneously, we believe AbBFN2 has the potential to accelerate discovery timelines, which could improve overall efficiency in drug development.

Explore AbBFN2 today – download the paper, try the demo on DeepChain, or dive into the open-source code.
1 In this work, we use the term “pipeline” to refer to a structured, multi-step methodological workflow for preclinical antibody optimisation, distinct from the broader use of “pipeline” to describe a company’s therapeutic development portfolio.