

Please read our extensive Privacy policy here. You can also read our Privacy Notice and our Cookie Notice
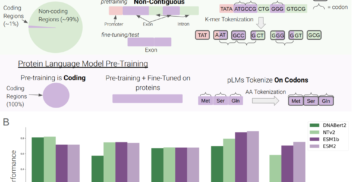
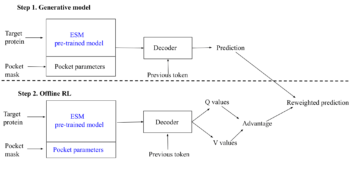
SegmentNT: annotating the genome at single-nucleotide resolution with DNA foundation models
Mar 2024

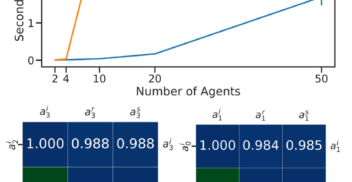
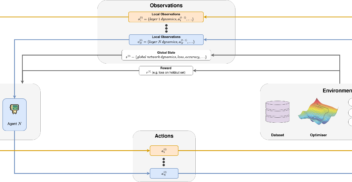
How much can change in a year? Revisiting Evaluation in Multi-Agent Reinforcement Learning
AAAI workshop Mar 2024
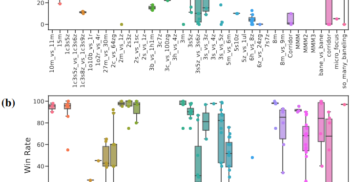
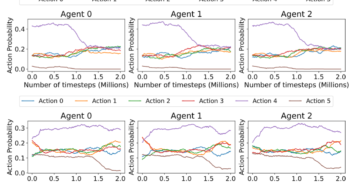
On Diagnostics for Understanding Agent Training Behaviour in Cooperative MARL
AAAI workshop Mar 2024
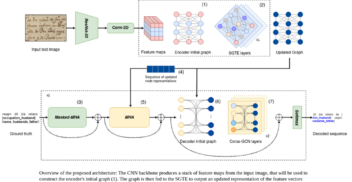
Graph Neural Networks for End-to-End Information Extraction from Handwritten Documents
WACV 2024 Mar 2024